A potential outcome is what an outcome variable woult take under a specific exposure(treatment). Before treatmet occurs, every unit has one potential outcome per exposure level, \(Y(x)\) for each x. Once an exposure happens, only one potential outcome is realised. The rest are counterfactual ie they exist in the causal model but not in the data.
This is the fundamental problem of causal inference. The individual causal effect \(Y(X_{1})\) - \(Y(X_{0})\) requirs both potential outcomes simultaneously. You observe exactly one. Every method in the potential outomes framework is an attempt to use observed data to substitute for missing counterfactuals under explicit assumptions that justify the substitution.
Ice-T, Spike and the counterfactual proxy
The book opens with Ice-T and Spike, two men who grew upin the same Los Angeles gang neighborhoods, ran jewelry heists together, and then diverged. Ice-T was discovered rapping and left the criminal life; Spike continued and received a 35 years to life sentence. The premise is that each serves as the other’s counterfactual.
Show code
librarian::shelf(tidyverse, kableExtra)tibble(person =c("Ice-T", "Spike"),path =c("Abandoned criminal life", "Continued criminal life"),outcome =c("Fame and Fortune", "35 years to life"),counterfactual_path =c("Did one more heist", "Abandoned Criminal Life"),missing_outcome =c("35 years to life", "Fame and fortune")) |>kbl(align ="lllll",col.names =c("Person", "Observed path", "Observed outcome", "Counterfactual path", "Missing outcome") ) |>kable_styling(bootstrap_options =c("striped", "hover", "condensed"),full_width =FALSE,position ="left") |>column_spec(1, bold =TRUE) |>column_spec(4:5, color ="grey40", italic =TRUE) |>add_header_above(c(" "=3, "Counterfactual (unobservable)"=2))
Counterfactual (unobservable)
Person
Observed path
Observed outcome
Counterfactual path
Missing outcome
Ice-T
Abandoned criminal life
Fame and Fortune
Did one more heist
35 years to life
Spike
Continued criminal life
35 years to life
Abandoned Criminal Life
Fame and fortune
The premise is appealig but does not hold perfectly. Musical talent is a plausible cause of Ice-T’s outcome independent of his decision to quit, which makes Spike a reasonable proxy for what Ice-T would have faced had he continued, but not necessarily a symmetric counterfactual the other way round. This is the same asymmetry problem in every observational analysis. The chapter uses the story to motivate why we work with averaged effects over population rather than individual counterfactuals, and why randomization or adjustment is needed to construct valid proxies.
Potential Outcomes vs Counterfactuals
A Counterfactual is a potential outcome that was not realised, it’s counter to the fact of what happened. Potential outcomes are defined before the exposure, agnostic to what actually occurs. In practice, the book treats the two terms as interchangeable; once exposure has happened, you’re always looking at one realised outcome and at least one counter to the fact
The ice cream simulation
The oracle table: all potential outcomes known
Ten individuals each have a chocolate happiness score and a vanila happiness score. This “Oracle” view, both potential outcomes visible simultaneously, is never available in practice, it exists here only to define what we are trying to estimate.
Show code
library(tibble)library(kableExtra)# Save the tibble to a variable so we can reference it in row_specpo_display <- po_data |>rename(ID = id,`Y(chocolate)`= y_chocolate,`Y(vanilla)`= y_vanilla,`Y(choc) - Y(van)`= causal_effect )po_display |>kbl(align ="cccc") |>kable_styling(bootstrap_options =c("striped", "hover", "condensed"),full_width =FALSE,position ="left" ) |>add_header_above(c(" "=1, "Potential outcomes"=2, "Individual causal effect"=1)) |>row_spec(0, bold =TRUE) |>row_spec(which(po_display$`Y(choc) - Y(van)`<0), color ="#c0392b") |>row_spec(nrow(po_display), bold =TRUE) |>footnote(general =paste0("True ATE = ", round(mean(po_data$y_chocolate), 2)," - ", round(mean(po_data$y_vanilla), 2)," = ", round(mean(po_data$causal_effect), 2),". Rows in red have negative individual causal effects (vanilla > chocolate for that person)." ),general_title ="" )
Potential outcomes
Individual causal effect
ID
Y(chocolate)
Y(vanilla)
Y(choc) - Y(van)
1
4
1
3
2
4
3
1
3
6
4
2
4
5
5
0
5
6
5
1
6
5
6
-1
7
6
8
-2
8
7
6
1
9
5
3
2
10
6
5
1
True ATE = 5.4 - 4.6 = 0.8. Rows in red have negative individual causal effects (vanilla > chocolate for that person).
What we actually observe under randomization
Assign each participant randomly (50/50) to one flavor. Now only the assigned potential outcome is observed; the counterfactual is missing. Individual causal effects become unknowable.
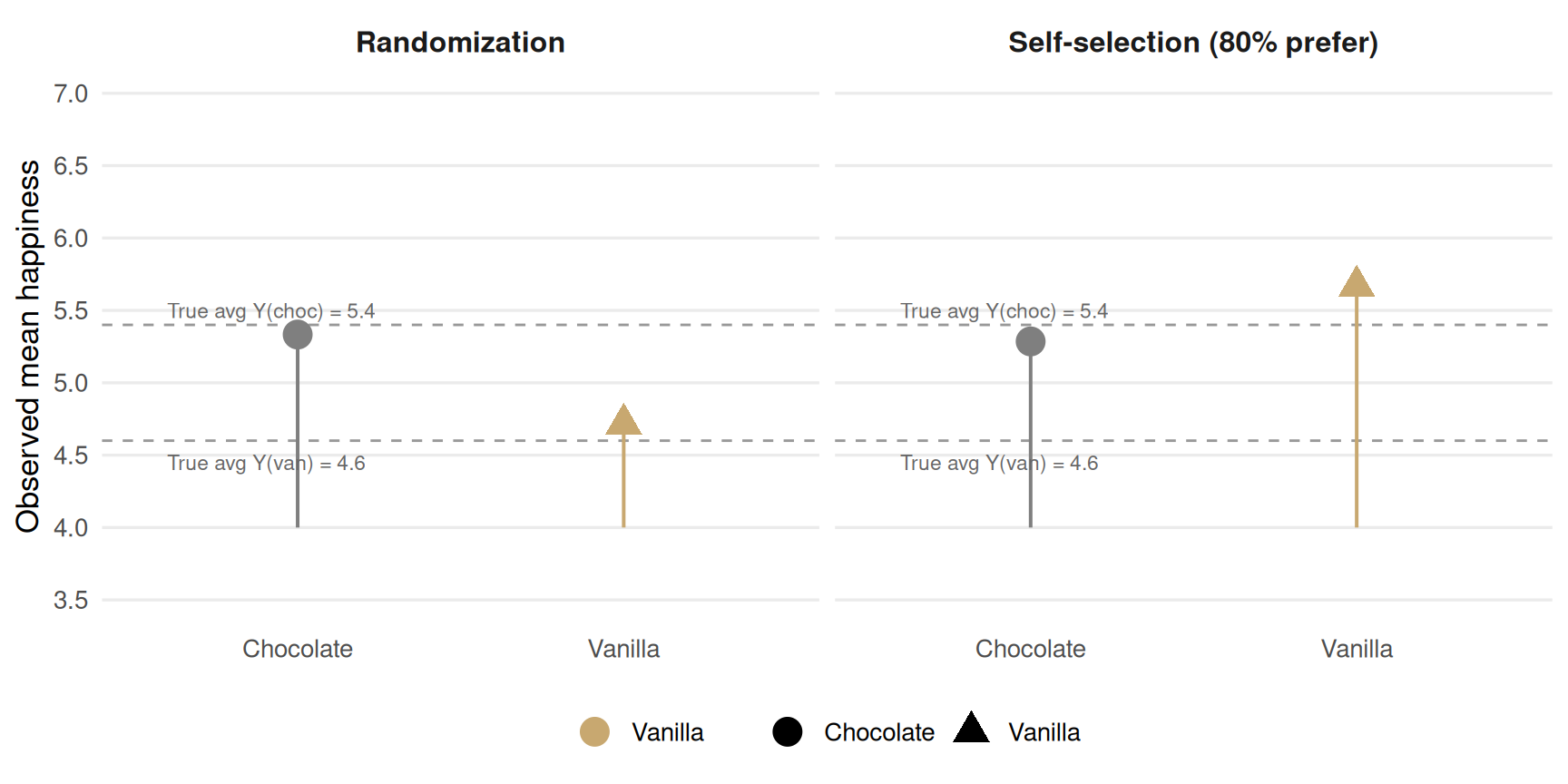
Figure 4.1: Group mean happiness by flavor under randomization (left) and preference-driven self-selection (right). Under randomization the contrast recovers the true ATE; under self-selection it reverses sign.
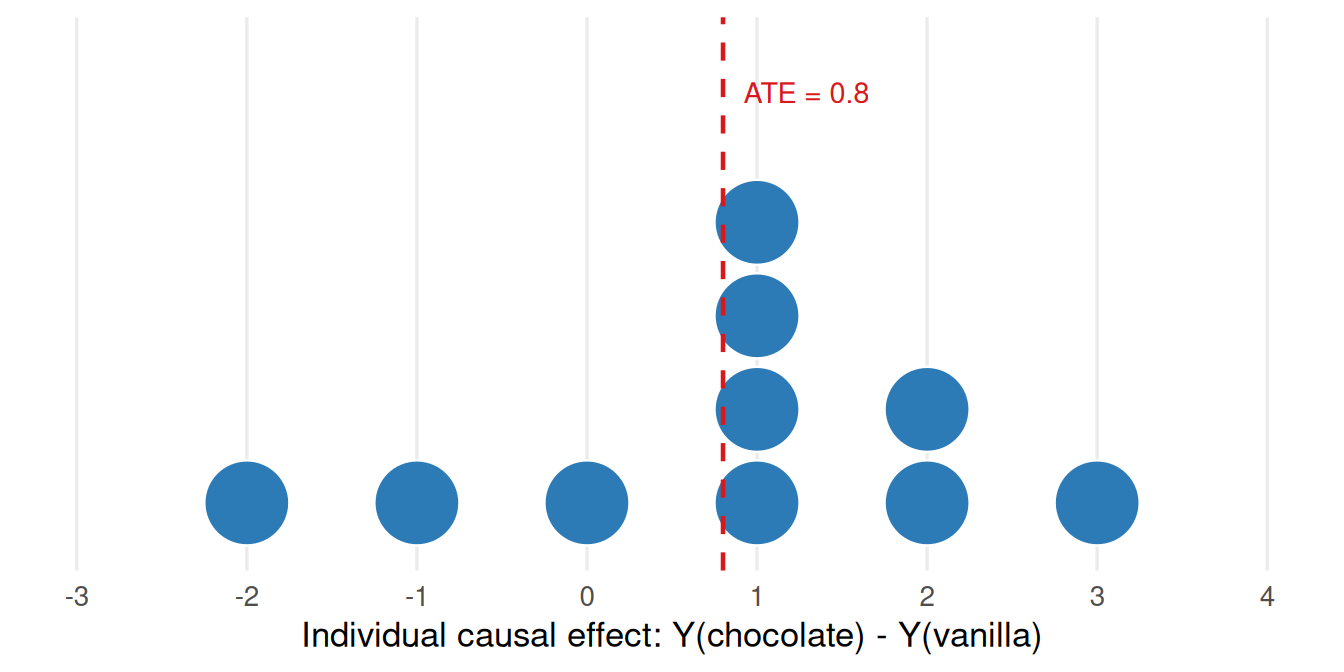
Figure 4.2: Distribution of individual causal effects from the oracle table. The ATE (0.8) is the mean, but individual effects range from -2 to +3. Negative effects (individuals who prefer vanilla) are the reason self-selection induces bias.
Causal Assumptions
For observed data to stand in missing counterfactuals, three identifiablity conditions have to hold. The book cals these the unconfoundedness assumptions, theyre required by the IPW, regression adjustment, g-computation, and most other methods covered. Miss one and you’re not estimating a causal effect anymore, whatever the statistics say.
Show code
tibble::tibble(Assumption =c("Exchangeability", "Positivity", "Consistency"),`Also called`=c("No confounding; ignorability; unconfoundedness","Probabilistic assumption; overlap","SUTVA (Stable Unit Treatment Value Assumption)" ),`Formal notation`=c("\\(Y(x) \\perp\\!\\!\\!\\perp X\\)","\\(P(X = x) > 0\\) for all \\(x\\)","\\(Y_{\\text{obs}} = X \\cdot Y(1) + (1-X) \\cdot Y(0)\\)" ),`Plain language`=c("Exposure assignment is independent of potential outcomes","Every unit has non-zero probability of each exposure level","Observed outcome = potential outcome under received exposure" )) |>kbl(escape =FALSE,align =c("l", "l", "c", "l"),booktabs =TRUE ) |>kable_styling(bootstrap_options =c("striped", "hover", "condensed"),full_width =TRUE ) |>column_spec(1, bold =TRUE) |>column_spec(3, monospace =TRUE)
Table 4.1: The three core identifiability conditions for unconfoundedness methods.
Assumption
Also called
Formal notation
Plain language
Exchangeability
No confounding; ignorability; unconfoundedness
\(Y(x) \perp\!\!\!\perp X\)
Exposure assignment is independent of potential outcomes
Positivity
Probabilistic assumption; overlap
\(P(X = x) > 0\) for all \(x\)
Every unit has non-zero probability of each exposure level
Consistency
SUTVA (Stable Unit Treatment Value Assumption)
\(Y_{\text{obs}} = X \cdot Y(1) + (1-X) \cdot Y(0)\)
Observed outcome = potential outcome under received exposure
The apples-to-apples principle
All three assumptions exist to solve the same problem; making sure the comparison groups are exchangeable, close enough that each can reasonably stand in for the other’s counterfactual. English speakers say “comparing apples to oranges”; other languages have their own versions:
Cheese and Chalk (UK)
Grandmothers and toads (Serbian)
Potatoes and sweet potatoes (Latin American Spanish)
The diagnostic question: do the groups differ in ways that are tied to both the exposure and the outcome? If yes, the comparison is broken before any statistics happen
Exchangeability
What exchangeability looks like and what breaks it
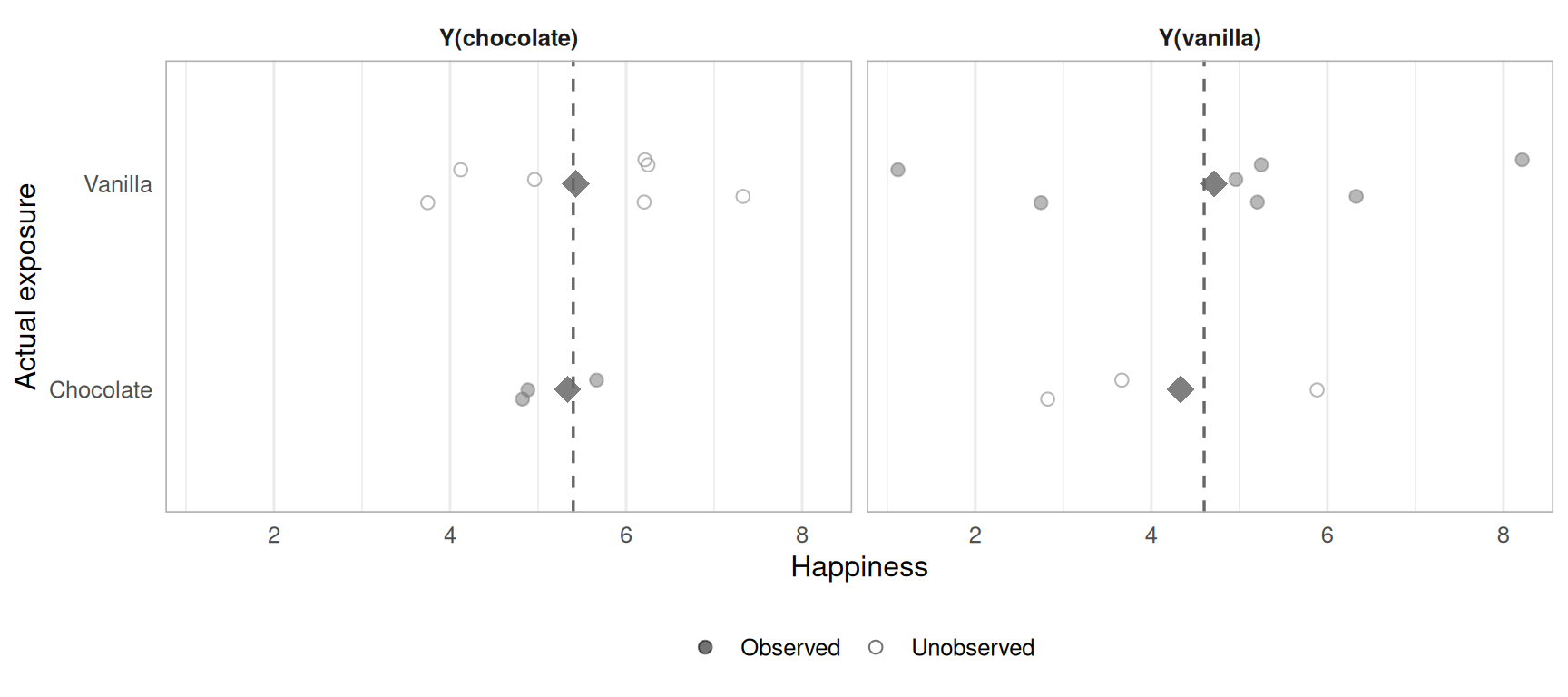
Under randomization, the two groups have the same distribution of potential outcomes on average. The observed average of \(Y_{i}(Chocolate)\) in the chocolate group is an unbiased estimate of the unobserved average of \(Y_{i}(Chocolate)\) in the vanilla group, and vice versa. This is the key to recovering ATE.
Figure 4.3: Potential outcomes by exposure group under randomization. Both groups’ observed averages (filled diamonds) are close to the true marginal means (dashed lines), confirming exchangeability.
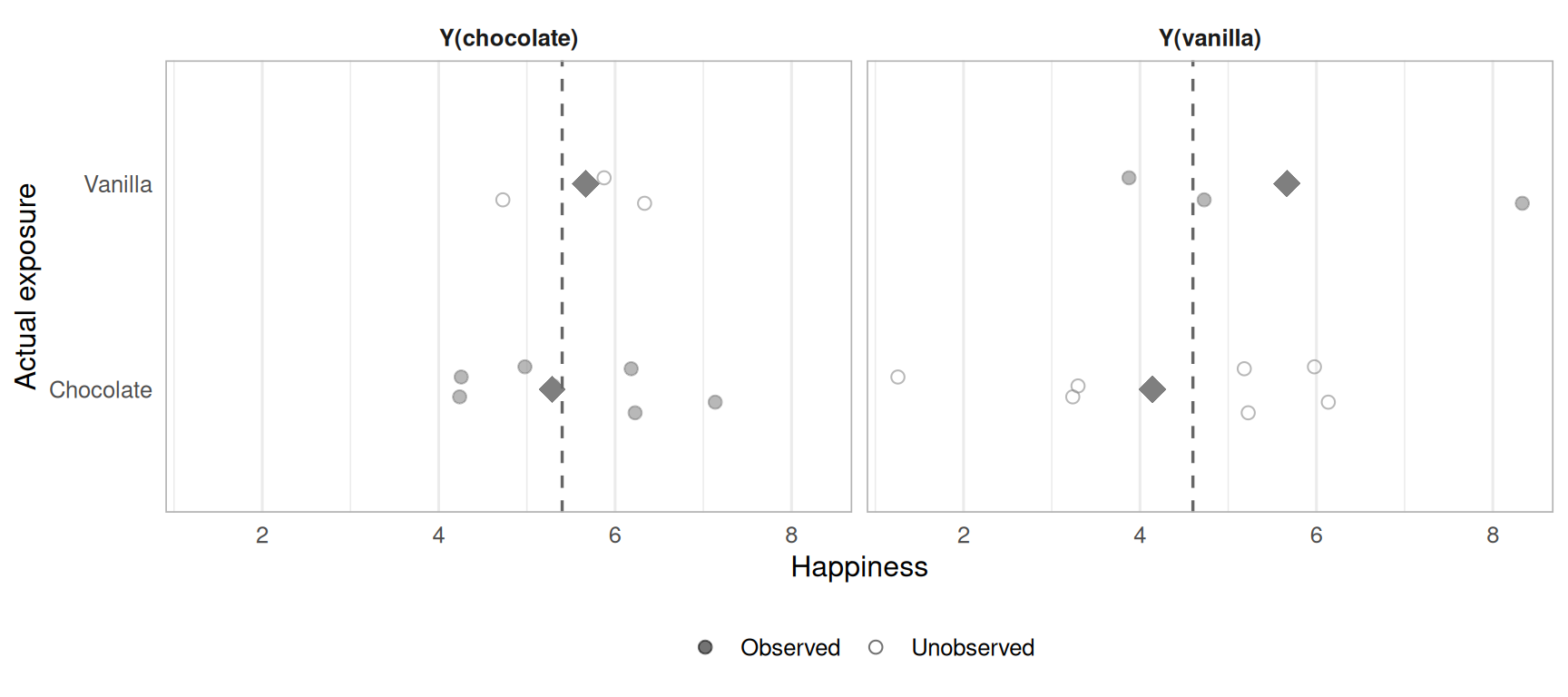
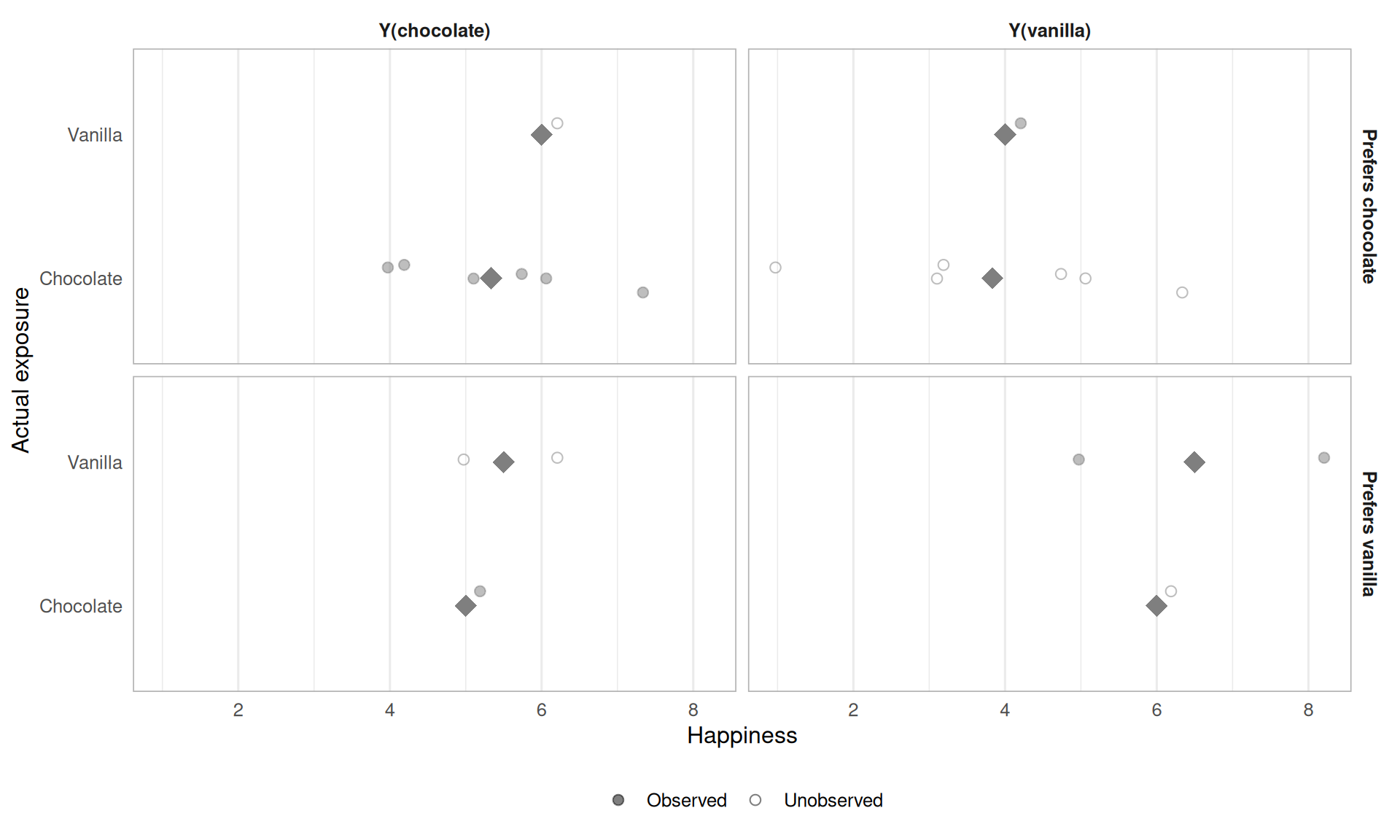
Under self-selection, people choose the flavor they prefer 80% of the time. Now Y(vanilla) averages diverge sharply by group, the chocolate group(who mostly prefer chocolate and avoided vanilla) has lower observed Y(vanilla) than the vanilla group. The groups are no longer exhangeable
Figure 4.4: Potential outcomes by exposure group under preference-driven self-selection. The Y(vanilla) averages differ markedly by group the chocolate group’s unobserved Y(vanilla) is systematically lower than the vanilla group’s. Exchangeability fails.
Conditional Exchangeability
Full exchangeability, \(Y(x) \\perp\\!\\!\\!\\perp X\), fails whenever exposure selection depends on potential outcomes. Conditional exchangeability, \(Y(x) \\perp\\!\\!\\!\\perp X | Z\), says the groups become exchangeable once you condition on Z. This is the operating assumption for all propensity score and regression adjustment methods.
Figure 4.5: Potential outcomes by exposure group, stratified by flavor preference. Within each stratum, the two groups have similar potential outcome averages conditional exchangeability holds even when marginal exchangeability does not.
Its credibility depends entirely on whether Z captures all common causes of exposure and outcome. Unmeasured confounders break it, and unlike positivity (checkable empirically), conditional exchangeability is unverifiable from data alone.
Positivity
Stochastic positivity violation
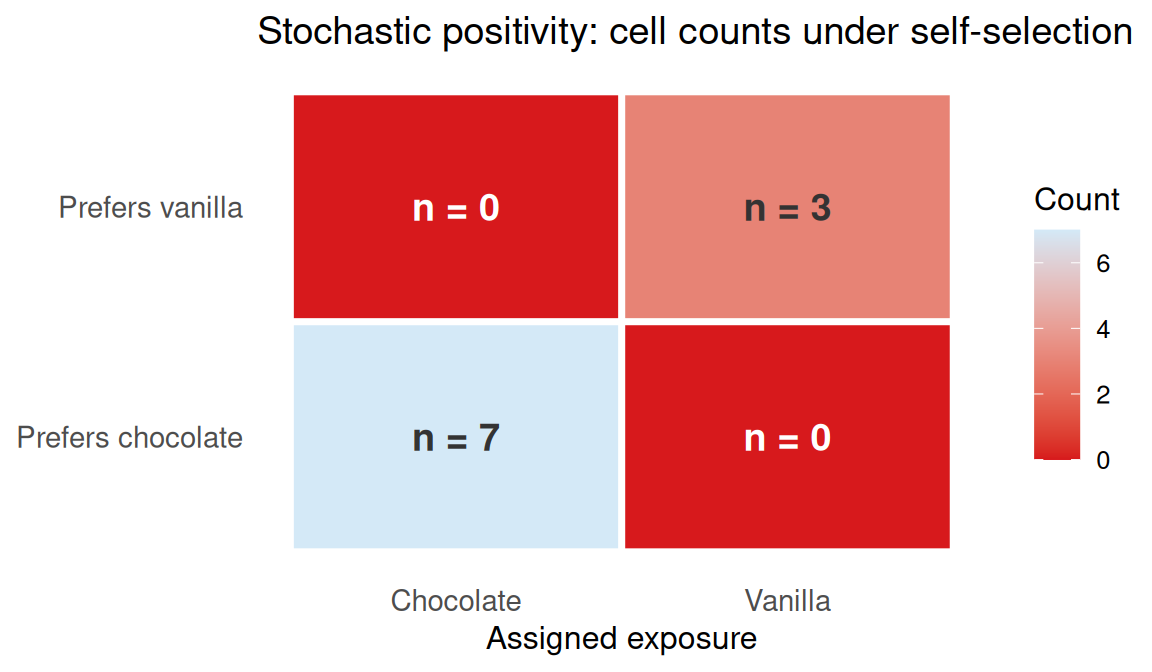
With n = 10 and 80% self-selection, some covariate-exposure cells end up empty by chance. We need observations in every stratum to estimate stratum specific effects.
Figure 4.6: Cell counts for each preference-by-exposure combination under preference-driven self-selection. Empty cells (n = 0) are stochastic positivity violations, no observations exist to estimate potential outcomes in those strata.
Structural positivity violation
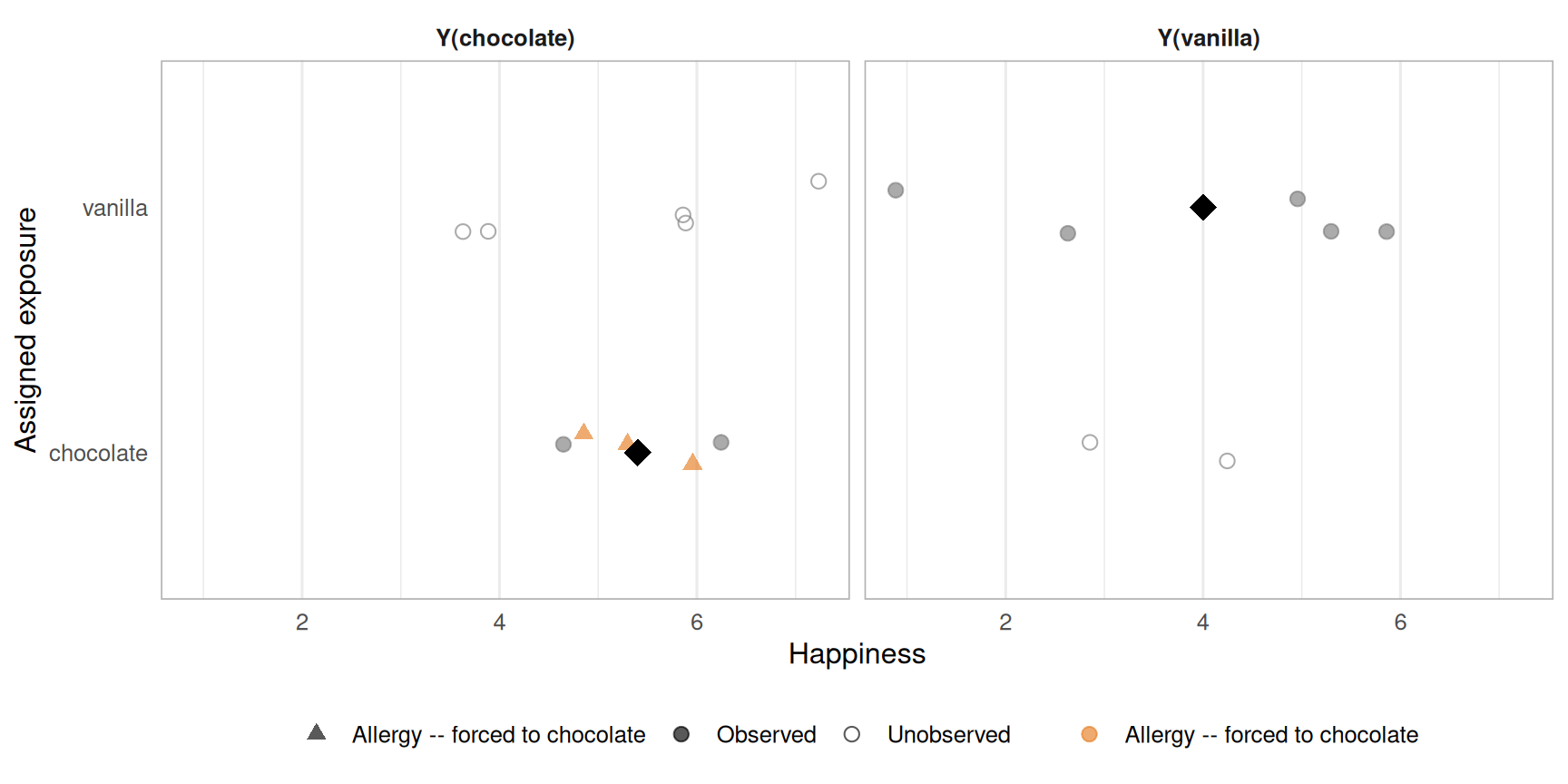
Structural violations occur when some units literally cannot receive a given exposure level. Participants with a vanilla allergy cannot be assigned vanilla, Y(vanilla) is undefined for them, not merely unobserved.
Figure 4.7: Potential outcomes under a structural positivity violation. Individuals with a vanilla allergy (orange) have no Y(vanilla) counterpart the potential outcome is undefined, not missing at random. Their presence in the chocolate group inflates the estimated Y(chocolate) average.
Show code
tibble(Type =c("Stochastic", "Structural"),Cause =c("Sampling variation produces empty exposure-covariate cells by chance","Some units cannot receive at least one exposure level by biology or circumstance" ),Example =c("With n = 10 and 80% self-selection, some preference-exposure strata end up with zero observations","Participants with a vanilla allergy cannot receive vanilla; Y(vanilla) is undefined for them" ),Fix =c("Larger samples; propensity scores or g-computation to extrapolate over covariate dimensions","Restrict eligibility criteria to exclude structurally ineligible units; modify the estimand to a population where positivity holds" )) |>kbl(align ="llll") |>kable_styling(bootstrap_options =c("striped", "hover", "condensed"),full_width =TRUE ) |>row_spec(0, bold =TRUE) |>column_spec(1, bold =TRUE, width ="9em") |>column_spec(2:4, width ="22em")
Table 4.2: Two forms of positivity violation
Type
Cause
Example
Fix
Stochastic
Sampling variation produces empty exposure-covariate cells by chance
With n = 10 and 80% self-selection, some preference-exposure strata end up with zero observations
Larger samples; propensity scores or g-computation to extrapolate over covariate dimensions
Structural
Some units cannot receive at least one exposure level by biology or circumstance
Participants with a vanilla allergy cannot receive vanilla; Y(vanilla) is undefined for them
Restrict eligibility criteria to exclude structurally ineligible units; modify the estimand to a population where positivity holds
Consistency
Consistency
Consistency requires that the observed outcome under X = x actually equals Y(x). It breaks in two ways.
Poorly-defined exposure: spoiled chocolate
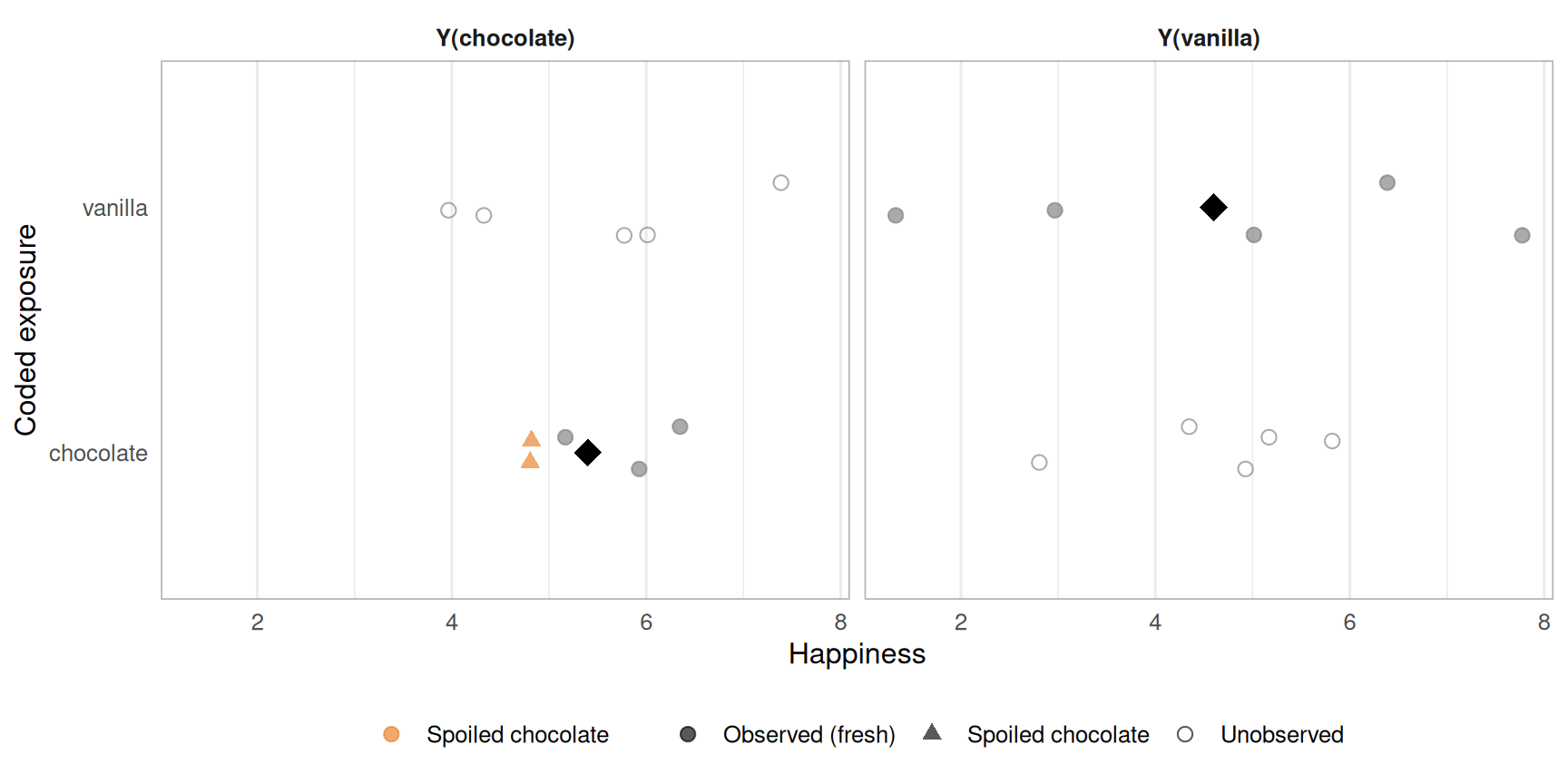
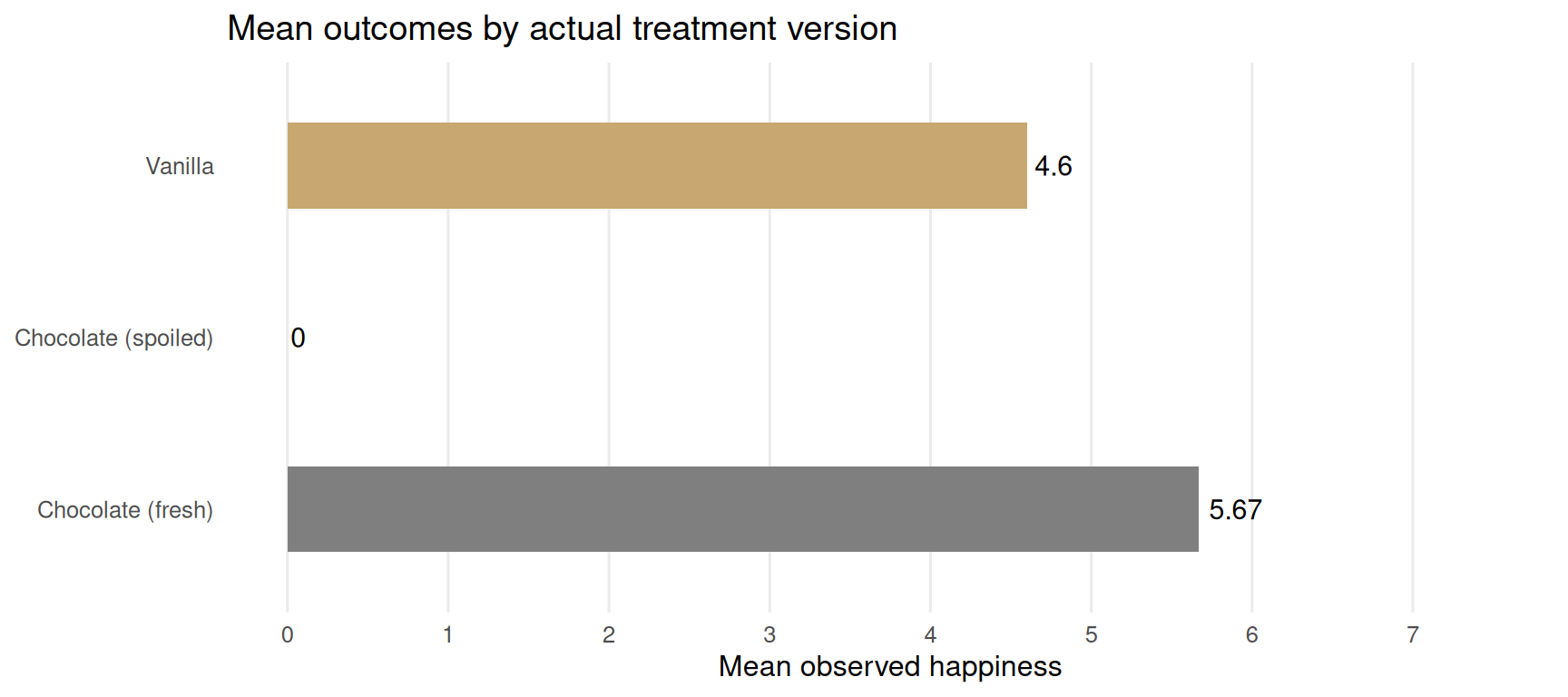
Two containers of chocolate exist, one fresh, one spoiled. Both are coded “chocolate.” The observed chocolate group is a mixture of Y(chocolate, spoiled = TRUE) and Y(chocolate, spoiled = FALSE), which have completely different potential outcomes.
Figure 4.8: Potential outcomes under a poorly-defined exposure. The observed Y(chocolate) average (black diamond) is a blend of fresh-chocolate and spoiled-chocolate outcomes. Spoiled individuals (orange) drag the average down and make the estimate uninterpretable.
Stratifying by the actual exposure label (chocolate fresh / chocolate spoiled / vanilla) recovers the correct estimates.
Figure 4.9: Potential outcomes after correcting for treatment version. Separating fresh and spoiled chocolate recovers the true Y(chocolate) average. The three-group contrast is now interpretable.
Interference: partner flavor effects
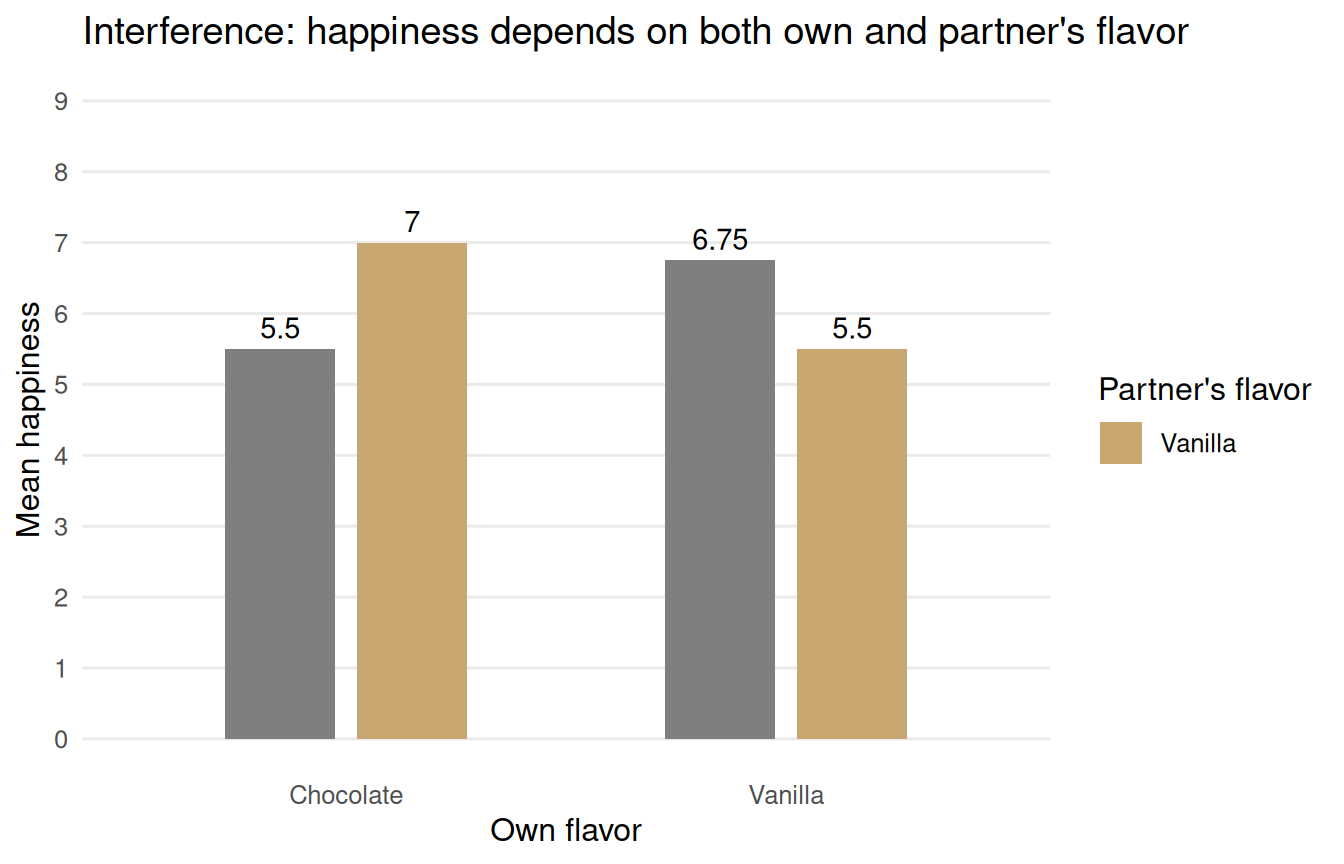
Each participant has a partner. Their happiness depends not only on their own flavor but also their partner’s, receiving a different flavor adds 2 happiness units. There are now four potential outcomes per person: Y(own, partner). A simple two-group contrast is estimating a mixture of these four quantities.
Figure 4.10: Mean happiness by own flavor and partner’s flavor combination. The simple two-group contrast (chocolate vs vanilla ignoring partner) estimates a mixture of four distinct potential outcomes. The effect of own flavor interacts with partner assignment.
Show code
tibble(Type =c("Poorly-defined exposure", "Interference"),Cause =c("Multiple treatment versions exist under a single exposure label","One unit's exposure changes another unit's potential outcome" ),Example =c("Spoiled and fresh chocolate both coded 'chocolate'; spoiled yields happiness = 0, fresh yields ~5.5","Partner receiving a different flavor adds 2 happiness units, Y depends on both own and partner's assignment" ),Fix =c("Record and stratify by treatment version; sharpen the exposure definition","Cluster-randomize at the partnership level; exclude interacting units; specify potential outcomes that index partner exposure explicitly" )) |>kbl(align ="llll") |>kable_styling(bootstrap_options =c("striped", "hover", "condensed"),full_width =TRUE ) |>row_spec(0, bold =TRUE) |>column_spec(1, bold =TRUE, width ="14em") |>column_spec(2:4, width ="20em")
Table 4.3: Two forms of consistency violation
Type
Cause
Example
Fix
Poorly-defined exposure
Multiple treatment versions exist under a single exposure label
Spoiled and fresh chocolate both coded 'chocolate'; spoiled yields happiness = 0, fresh yields ~5.5
Record and stratify by treatment version; sharpen the exposure definition
Interference
One unit's exposure changes another unit's potential outcome
Partner receiving a different flavor adds 2 happiness units, Y depends on both own and partner's assignment
Cluster-randomize at the partnership level; exclude interacting units; specify potential outcomes that index partner exposure explicitly
Table 4.4: How study designs meet the three identifiability conditions
Assumption
Ideal RCT
Realistic RCT
Observational
Consistency (well-defined exposure)
😄
🤷
🤷
Consistency (no interference)
🤷
🤷
🤷
Positivity
😄
😄
🤷
Exchangeability
😄
🤷
🤷
Smiley = satisfied by default. Shrug = solvable but not guaranteed.
Randomization in an ideal RCT decouples exposure from potential outcomes (exchangeability) and fixes known exposure probabilities (positivity). Interference remains a design challenge regardless of randomization. In realistic RCTs, non-adherence, selective dropout, and implementation variation can reintroduce every problem the randomization was meant to eliminate. Observational studies carry none of these guarantees and must address all three assumptions through design choices and analytic decisions.
The target trial framework
Hernan and Robins (2016) proposed that every causal analysis, whether randomized or not, should be anchored to an explicit protocol: a target trial. The seven protocol elements and the assumptions each addresses:
Table 4.5: Target trial protocol elements mapped to the identifiability conditions they address
Protocol element
Consistency (well-defined)
Consistency (interference)
Positivity
Exchangeability
Eligibility criteria
✔
✔
✔
✔
Exposure definition
✔
✔
✔
✔
Assignment procedures
✔
✔
✔
✔
Follow-up period
✔
Outcome definition
✔
✔
Causal contrast of interest
✔
✔
Analysis plan
✔
✔
✔
✔
Eligibility criteria prevent structural positivity violations by excluding units for whom an exposure level is impossible, and constrain the population to one where exchangeability is more defensible. Precise exposure definitions eliminate treatment version heterogeneity (consistency) and identify positivity and exchangeability requirements. Assignment procedures address all three most directly, randomization solves exchangeability and positivity simultaneously. Follow-up period is primarily an exchangeability lever; incomparable observation windows introduce differential selection. Outcome definition helps exchangeability by identifying prognostic factors. The causal contrast can be chosen to relax positivity demands (ATT vs ATE). The analysis plan makes the exchangeability assumption explicit and auditable.
Show code
tibble(`Protocol step`=c("Eligibility criteria","Exposure definition","Assignment procedures","Follow-up period","Outcome definition","Causal contrast","Analysis plan" ),`Target trial`=c("Age 18-65; no lactose intolerance or ingredient allergy; entered store within study week","100g vanilla or chocolate ice cream, Don and Jerzy brand, served in a bowl","Randomized 50/50, non-blinded","Start: eligibility met and flavor assigned. End: 30 minutes post-assignment","Happiness (1-10), gold-standard tool","Average Treatment Effect (ATE)","IPW weighted for baseline happiness, age, income, education, physical activity, self-rated physical and mental health, quality of relationships, flavor preference" ),`Observational emulation`=c("Same as target trial","Same as target trial","Flavor matches observed choice; randomization emulated via IPW","Same as target trial","Same as target trial","Same as target trial","IPW adjusted for confounders (baseline happiness, age, flavor preference) plus additional baseline prognostic variables (income, education, physical activity, self-rated health, quality of relationships)" )) |>kbl(align ="lll") |>kable_styling(bootstrap_options =c("striped", "hover", "condensed"),full_width =TRUE ) |>row_spec(0, bold =TRUE) |>column_spec(1, bold =TRUE, width ="14em") |>column_spec(2:3, width ="28em")
Table 4.6: Target trial protocol and observational emulation for the ice cream happiness study
Protocol step
Target trial
Observational emulation
Eligibility criteria
Age 18-65; no lactose intolerance or ingredient allergy; entered store within study week
Same as target trial
Exposure definition
100g vanilla or chocolate ice cream, Don and Jerzy brand, served in a bowl
Same as target trial
Assignment procedures
Randomized 50/50, non-blinded
Flavor matches observed choice; randomization emulated via IPW
Follow-up period
Start: eligibility met and flavor assigned. End: 30 minutes post-assignment
Same as target trial
Outcome definition
Happiness (1-10), gold-standard tool
Same as target trial
Causal contrast
Average Treatment Effect (ATE)
Same as target trial
Analysis plan
IPW weighted for baseline happiness, age, income, education, physical activity, self-rated physical and mental health, quality of relationships, flavor preference
IPW adjusted for confounders (baseline happiness, age, flavor preference) plus additional baseline prognostic variables (income, education, physical activity, self-rated health, quality of relationships)
Excluding allergy sufferers removes structural positivity violations for Y(vanilla). The standardized serving specification eliminates the most obvious treatment version problem. IPW in the observational arm attempts to recover exchangeability by reweighting the observed covariate distribution. The explicit confounder list in the analysis plan makes the exchangeability assumption auditable, which does not make it verified, but at least makes it falsifiable by a reviewer who disagrees with the assumed causal structure.